For all it’s capability, it might be hard to believe that Data Lake’s actually cost less than traditional data warehousing – significantly less. Quotes range from 10 to 100 times less or 75% less.
Processing and storage costs using traditional data warehouse and RDBMS technologies are typically in the 10’s of thousands of dollars per terabyte. By comparison, costs on Hadoop are in the 100’s of dollars per terabyte. That’s a 100x cost reduction. Source: Sourcethought
Big Data is a tremendous capability differentiator AND it reduces cost. That’s a Big (Data) Return on Investment. So:
Creating a Data Lake is often the first and best step for an organization to begin utilizing Big Data as a strategy.
With last week’s discussion on Data Lakes, it should be noted how valuable the capability is. Here is one example of how a data lake is utilized for healthcare.
UC Irvine Medical Center maintains millions of records for more than a million patients, including radiology images and other semi-structured reports, unstructured physicians’ notes, plus volumes of spreadsheet data. To solve the challenge the hospital faced with data storage, integration, and accessibility, the hospital created a data lake based on a Hadoop architecture, which enables distributed big data processing by using broadly accepted open software standards and massively parallel commodity hardware.
Hadoop allows the hospital’s disparate records to be stored in their native formats for later parsing, rather than forcing all-or-nothing integration up front as in a data warehousing scenario. Preserving the native format also helps maintain data provenance and fidelity, so different analyses can be performed using different contexts. The data lake has made possible several data analysis projects, including the ability to predict the likelihood of readmissions and take preventive measures to reduce the number of readmissions. Source: price waterhouse cooper –
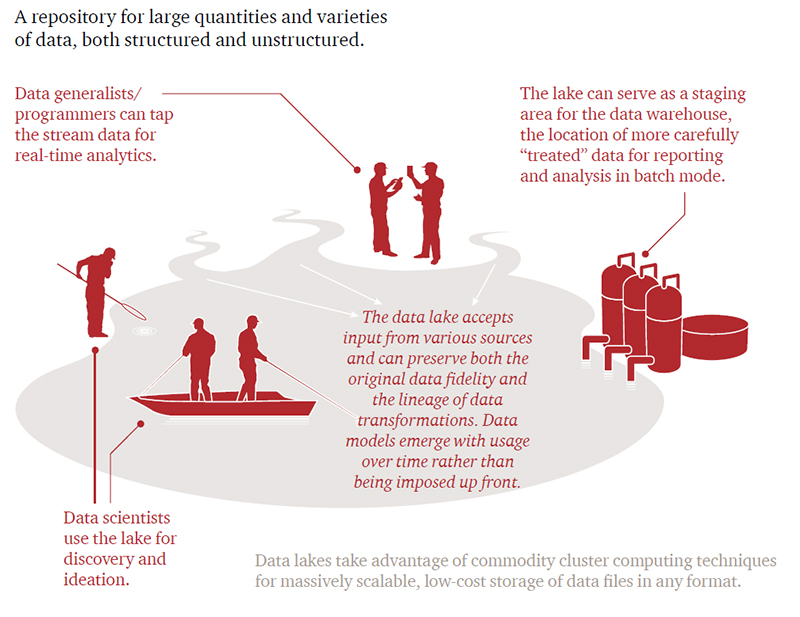
Price Waterhouse Cooper also has a nice graphic on how an organization utilizes the Data Lake.
