It’s your fault.
No it’s the other person’s fault.
It’s the guy who cut you off in traffic.
It’s “customer service.”
It’s the government.
It’s the weather.
It’s global warming.
It’s the way things go.
A tree falls in the forest. A roof falls in. A business fails. A stock market crashes. A disease spreads.
Sh!t happens
Who or what caused it? Cause and effect – causality – is deeply woven into our lives.
Figuring out who or what caused something is a universal application of everyday life as well as one of global consequence. We want to know why something happened, regardless of good or bad outcomes.
Researchers use causality to test whether a drug has the desired effects as well as to control the less desirable side effects. It’s used by scientists to figure out the common cold or/and the secrets of the cosmos. What-caused-it figures out who is going to pay for damages – for the automobile accident or for global warming. It’s used by governments to develop regulations and uphold laws.
Knowing what caused what not only tries to explain what already happened, it also leans forward into the future. Causality is used for the ultimate gold – prediction. You use it to keep your finances and your safety. Business tries to predict who is going to buy what. Weather forecasters use causality to keep us dry as well as out of danger.
If we know what causes what, we can avoid the unfortunate and encourage the beneficial. So why doesn’t causality work?
Causality is a very flawed practice
Cause and effect is largely opinion. Consider the controversy over global warming. Do too many cars burning gas melt the polar ice caps? Are there too many people breathing too much? Is it a wobble in the earth’s rotation? Is it just … the way it goes? Is the globe even warming?
The debate consumes some of the greatest minds of science. Then politics and politicians become involved. Other non-experts but prominent participants such as actors and public figures weigh in. Finally, the “average” consumer and citizen have say in the truth or perception as well. Should each person’s opinion have equal weight? (when they don’t)
Causality is assailed by lots of variables and lots of interpretations, which not only seek to figure out what has happened but also how to affect the future.
So can we change global warming? Do we want to change it? What happens when we do change it? Will we get the desired results?
Getting Personal
We all want to know cause and effect, so let’s look at some personal examples – weight control. Does eating a doughnut make you fat? Does it take eating a doughnut every day to make you fat? What if you’re one of those really skinny people? What if you ran a mile or a marathon after that doughnut?
What about cancer? Smoking = cancer, right? It’s not just one cigarette though. Is it one year of smoking? Day 366 or many years? Just how many does it take and what other factors increase or decrease that opportunity? That’s another causality factor. How can you explain those that smoke for decades without getting cancer?
Real or Perceived?
People like the security that numbers and calculations provide. Causality is no exception. There is a preconception of fairness that 2 + 2 = 4 and no one gets hurt. Simple addition though doesn’t exist in a bubble (unless you’re a mathematician). We use numbers for decisions. Small decisions are whether to purchase those cool shoes by whether the bank account supports it. Traffic engineers quantify what is safe with speed limits, which makes enforcing those rules “easier”.
Big decisions are global warming or poverty or war or whether a corporation or a government is operating in the black or the red. Unfortunately like any good story, numbers can be manipulated, either by ignorance or intent – ask those who invested in Enron and Goldman Sachs.
Mistaken Identity
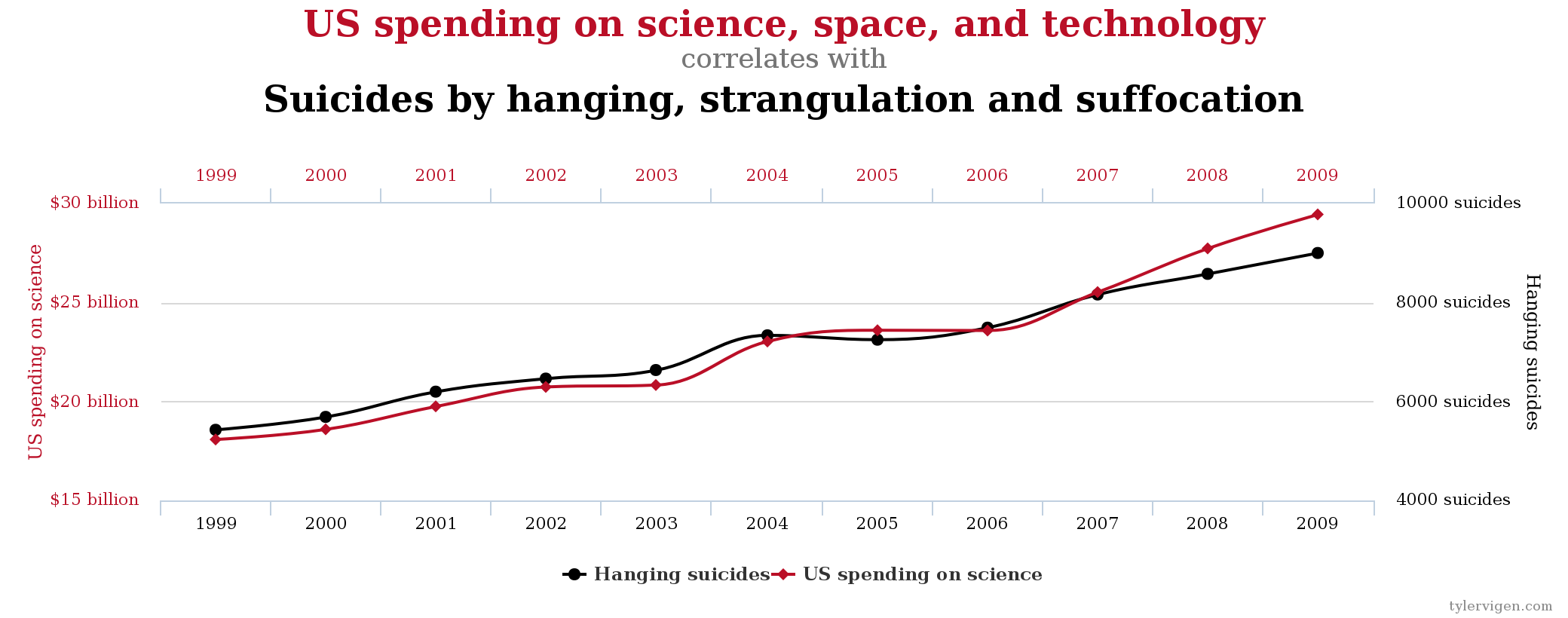
So causality often uses numbers for quantifying things that are a bit fuzzy. But when is it causality or its misunderstood cousin – correlation? This graph represents a strong correlation between US spending on science and technology and an increase in suicide by strangulation. A strong correlation does not mean that financing more STEM leads to more suicides. That’s the difference between correlation and causality, a fine line we are able to appreciate given an obvious scenario.
What if it’s not so obvious?

Gorilla in the Room
In The Invisible Gorilla Christopher Chabris and Daniel Simons explore intuition via a psychology experiment demonstrating how we overlook the obvious while concentrating on a task at hand. Survey participants are asked to count the passes while watching a video of players passing a basketball. During all this passing, a gorilla comes in the middle of the circle beating his chest and then departs.
Recreated in numerous scenarios in numerous countries, half the subjects never notice the gorilla.
The lesson? The authors use this experiment to underlie six areas in which our data collecting minds short circuit: attention, confidence, knowledge, memory, potential and yes, cause. Their chapter on causation centers on how people depend upon pattern recognition to solve problems or prevent them from occurring.
A physician cobbles symptoms together with personal experience and training to fix what ails you. A stock market trader does the same to make money. A parent tries to guide their child to safety and prosperity using their successes and failures. As crowds or governments or societies, we perpetually absorb environmental factors and interpolate results based on causality.
“Our world is systematically biased to perceive meaning rather than randomness and to infer cause rather than coincidence. And we are usually completely unaware of these biases.” P.154
Our minds have fascinatingly adapted to interpolate vastly more complicated situations. It’s also disturbing that biases build up like plaque in which we are unaware of the distortion.
Even if you think you’re an EXPERT on correlation versus causality, watch this Ted Talk and personal awareness quiz. Test your perspective of the world and learn some pretty cool data points.
Big Data Bias
How about Big Data? Big Data is not immune to the misdirections of faulty intuition. Like a bigger hammer, the momentum of Big Data could be perceived – or utilized – inaccurately with that much more destruction.
The glory though is that Big Data can overcome those causality challenges because of the Big-ness of the Data. The volume, velocity and variety usurp sampling “thinking”, hypothesis testing and small data limitations.
Small Thinking
This Khan Academy lesson in causality and correlation demonstrates the trip ups of small data sets and hypothesis testing. Using very little data from a small but statistically significant sample, an article suggests that one thing – eating breakfast – can decrease childhood obesity. The author never relays eating breakfast prevents obesity. As the lesson expounds, the careful word selection includes enough suggestion while omitting some relationships.
It’s a Wild World
In this example and in every hypothesis test, a plethora of variables must be held constant in order to create any deductions from the experiment. Like the examples above regarding eating donuts or preventing cancer, a hypothesis test tries to still a moment in time to get an answer when the reality of life is much more complex. Life an open system, subject to a world of whims and multiplying factors. Life is chaotic, vast dynamic systems sensitive to initial conditions that divine behavior.
The fault with small data can be overcome with Big Data capability. Big Data captures more, holds more and manipulates more data on a level we are really just beginning to comprehend. That transformation begins with removing the plaque of small data thinking.
Big Data is best deployed en masse, collecting and digesting mass quantities of volume and variety of sources. Without hypothesis testing, the information is observed for the patterns and outliers that arise. Unlike the doctors and stock brokers and parents, Big Data weaves without bias.
So It’s Only Natural
Causality is natural. We do it without thinking, which is both a survival mechanism and a fault. We draw conclusions from information and we suffer sometimes from those derivations from incorrect assumptions. Although errant thinking can be overcome by careful thinking and rigorous process, some preconceptions will always elude us.
Big Data is subject to the same bias errors, and it can be even worse because of the volume, velocity and variety of data. But Big Data is a new methodology capability. That capability is still being explored and it needs to be done outside of small data context.
The signal in the noise though is brilliant. It can comprehend solutions we would never dreams and it will solve problems we didn’t think possible. Think Big. It’s coming.
More resources:
Why you should stop worrying about deep learning and deepen your understanding of causality instead